The Evolving Landscape of LLM- and VLM-Integrated Reinforcement Learning
2025·,,, ,,,,·
0 min read
,,,,·
0 min read
S. Schoepp
M. Jafaripour
Y. Cao
T. Yang
Fatemeh Abdollahi
S. Golestan
Z. Sufiyan
O. R. Zaiane
M. E. Taylor
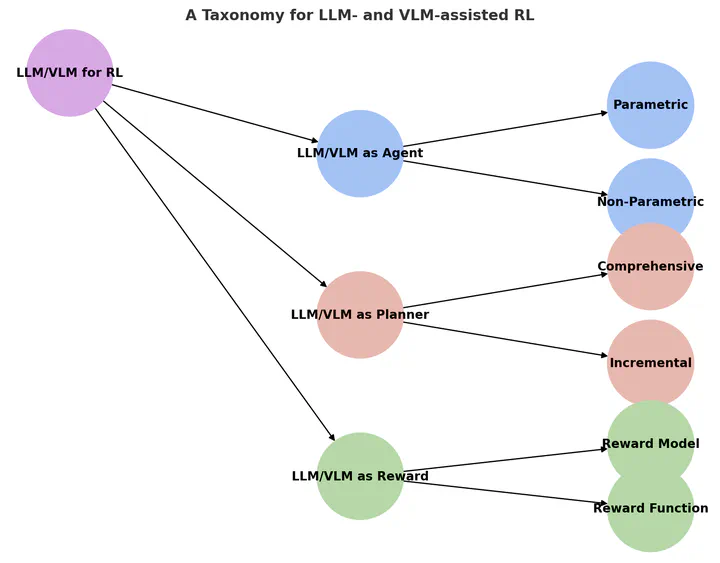 Reproduced from Figure 1 of the paper
Reproduced from Figure 1 of the paperAbstract
Reinforcement learning (RL) has shown impressive results in sequential decision-making tasks. Meanwhile, Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged, exhibiting impressive capabilities in multimodal understanding and reasoning. These advances have led to a surge of research integrating LLMs and VLMs into RL. In this survey, we review representative works in which LLMs and VLMs are used to overcome key challenges in RL, such as lack of prior knowledge, long-horizon planning, and reward design. We present a taxonomy that categorizes these LLM/VLM-assisted RL approaches into three roles: agent, planner, and reward. We conclude by exploring open problems, including grounding, bias mitigation, improved representations, and action advice. By consolidating existing research and identifying future directions, this survey establishes a framework for integrating LLMs and VLMs into RL, advancing approaches that unify natural language and visual understanding with sequential decision-making.
Publication
Submitted to IJCAI 2025: The 34th International Joint Conference on Artificial Intelligence